Apify Dataset
Overview
Apify is a web scraping and web automation platform providing both ready-made and custom solutions, an open-source JavaScript SDK and Python SDK for web scraping, proxies, and many other tools to help you build and run web automation jobs at scale.
The results of a scraping job are usually stored in the Apify Dataset. This Airbyte connector provides streams to work with the datasets, including syncing their content to your chosen destination using Airbyte.
To sync data from a dataset, all you need to know is your API token and dataset ID.
You can find your personal API token in the Apify Console in the Settings -> Integrations and the dataset ID in the Storage -> Datasets.
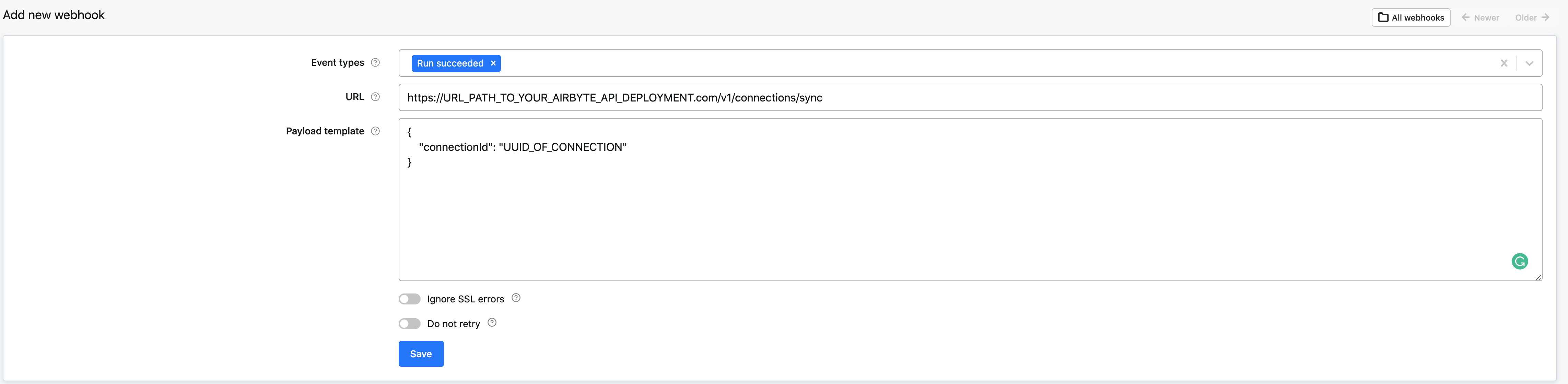
Running Airbyte sync from Apify webhook
When your Apify job (aka Actor run) finishes, it can trigger an Airbyte sync by calling the Airbyte API manual connection trigger (POST /v1/connections/sync). The API can be called from Apify webhook which is executed when your Apify run finishes.
Features
| Feature | Supported? |
|---|---|
| Full Refresh Sync | Yes |
| Incremental Sync | Yes |
Performance considerations
The Apify dataset connector uses Apify Python Client under the hood and should handle any API limitations under normal usage.
Streams
dataset_collection
dataset
- Calls
https://api.apify.com/v2/datasets/{datasetId}(docs) - Properties:
item_collection
- Calls
api.apify.com/v2/datasets/{datasetId}/items(docs) - Properties:
- Limitations:
- The stream uses a dynamic schema (all the data are stored under the
"data"key), so it should support all the Apify Datasets (produced by whatever Actor).
- The stream uses a dynamic schema (all the data are stored under the
item_collection_website_content_crawler
- Calls the same endpoint and uses the same properties as the
item_collectionstream. - Limitations:
- The stream uses a static schema which corresponds to the datasets produced by Website Content Crawler Actor. So only datasets produced by this Actor are supported.
Reference
Config fields reference
Changelog
Expand to review
| Version | Date | Pull Request | Subject |
|---|---|---|---|
| 2.1.6 | 2024-06-04 | 39010 | [autopull] Upgrade base image to v1.2.1 |
| 2.1.5 | 2024-04-19 | 37115 | Updating to 0.80.0 CDK |
| 2.1.4 | 2024-04-18 | 37115 | Manage dependencies with Poetry. |
| 2.1.3 | 2024-04-15 | 37115 | Base image migration: remove Dockerfile and use the python-connector-base image |
| 2.1.2 | 2024-04-12 | 37115 | schema descriptions |
| 2.1.1 | 2023-12-14 | 33414 | Prepare for airbyte-lib |
| 2.1.0 | 2023-10-13 | 31333 | Add stream for arbitrary datasets |
| 2.0.0 | 2023-09-18 | 30428 | Fix broken stream, manifest refactor |
| 1.0.0 | 2023-08-25 | 29859 | Migrate to lowcode |
| 0.2.0 | 2022-06-20 | 28290 | Make connector work with platform changes not syncing empty stream schemas. |
| 0.1.11 | 2022-04-27 | 12397 | No changes. Used connector to test publish workflow changes. |
| 0.1.9 | 2022-04-05 | PR#11712 | No changes from 0.1.4. Used connector to test publish workflow changes. |
| 0.1.4 | 2021-12-23 | PR#8434 | Update fields in source-connectors specifications |
| 0.1.2 | 2021-11-08 | PR#7499 | Remove base-python dependencies |
| 0.1.0 | 2021-07-29 | PR#5069 | Initial version of the connector |